Erkennen Sie ein Foto, ein Lied, die Gewohnheit eines Benutzers. Mit künstlicher Intelligenz ist es bereits möglich. Aber warum ist es wichtig und wie beeinflusst es unsere Lebensweise?
Bevor wir diese Frage beantworten, müssen wir einen Schritt zurücktreten, um den Unterschied zwischen zu erklären Artificial Intelligence (KI), Maschinelles lernen (ML) und Tiefes Lernen (DL), Begriffe, die oft verwechselt werden, aber eine genaue Bedeutung haben.
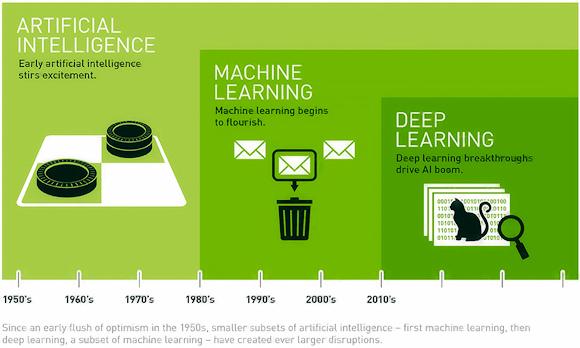
Um die Grundidee zu erklären, verwenden wir ein Bild (Eröffnung) von der NVIDIA-Website.
Aus dem Bild ist ersichtlich, dass der Begriff KI ein allgemeines Konzept von ML ist, das wiederum ein allgemeineres Konzept von DL ist. Aber nicht nur. In der Tat, wie wir die ersten Algorithmen von sehen tiefe Lernen Sie wurden vor etwas mehr als 10 Jahren geboren, im Gegensatz zu künstlicher Intelligenz, die um die 50er Jahre mit den ersten Sprachen wie LISP und PROLOG mit dem Ziel geboren wurde, die Fähigkeiten der menschlichen Intelligenz zu imitieren.
Die ersten Algorithmen der künstlichen Intelligenz beschränkten sich darauf, eine bestimmte mögliche Anzahl von Aktionen nach einer bestimmten, vom Programmierer definierten Logik auszuführen (wie beim Dame- oder Schachspiel).
Durch die Maschinelles Lernenhat sich die künstliche Intelligenz durch sogenannte überwachte und unüberwachte Lernalgorithmen mit dem Ziel entwickelt, mathematische Modelle des automatischen Lernens auf der Grundlage einer großen Menge von Eingabedaten zu erstellen, die die „Erfahrung“ der künstlichen Intelligenz darstellen.
Beim überwachten Lernen ist es zum Erstellen des Modells notwendig, die KI zu trainieren, indem jedem Element ein Label zugewiesen wird: Wenn ich beispielsweise Obst klassifizieren möchte, mache ich Fotos von vielen verschiedenen Äpfeln und beschrifte das Modell mit "Apfel". also für Birne, Banane usw.
Beim unüberwachten Lernen ist der Prozess umgekehrt: Ausgehend von verschiedenen Obstbildern muss ein Modell erstellt werden, und das Modell muss die Etiketten entsprechend den Eigenschaften extrahieren, die Äpfel, Birnen und Bananen gemeinsam haben.
Die Modelle von Maschinelles Lernen supervised werden bereits von Antiviren- und Spamfiltern, aber auch im Marketingbereich wie die von Amazon vorgeschlagenen Produkte verwendet.
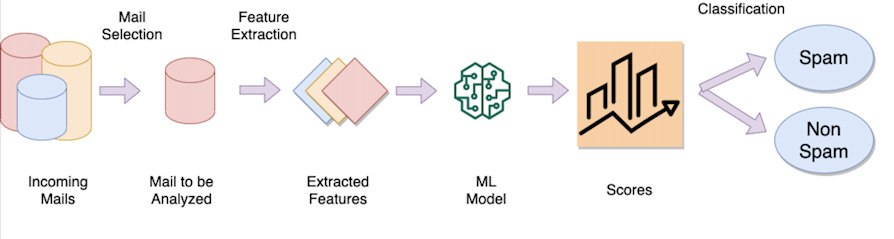
Das Beispiel des Spamfilters
Die Idee hinter einem E-Mail-Spamfilter besteht darin, ein Modell zu trainieren, das aus Hunderttausenden (wenn nicht Millionen) von E-Mails „lernt“ und jede E-Mail als „kennzeichnet“. Spam oder legitim. Nachdem das Modell trainiert wurde, umfasst die Klassifizierungsoperation:
Extrahieren besonderer Merkmale (sog. Merkmale) wie z. B. die Wörter des Textes, der Absender der E-Mail, die Quell-IP-Adresse usw.
Berücksichtigen Sie eine „Gewichtung“ für jedes extrahierte Merkmal (wenn der Text beispielsweise 1000 Wörter enthält, können einige von ihnen diskriminierender sein als andere, wie das Wort „Viagra“, „Porno“ usw., sie haben eine andere Gewichtung als Guten Morgen, Universitäten usw.)
Führen Sie eine mathematische Funktion aus, die unter Verwendung von Eingabemerkmalen (Wörter, Absender usw.) und ihrer jeweiligen Gewichtung einen numerischen Wert zurückgibt
Überprüfen Sie, ob dieser Wert über oder unter einem bestimmten Schwellenwert liegt, um festzustellen, ob die E-Mail legitim ist oder als Spam zu betrachten ist (Klassifizierung).
Künstliche Neuronen
Kommen Sie detto, il Tiefes Lernen ist ein Zweig der Maschinelles Lernen. Der Unterschied zu Maschinelles Lernen Es ist die Rechenkomplexität, die riesige Datenmengen mit einer „geschichteten“ Lernstruktur aus künstlichen neuronalen Netzen ins Spiel bringt. Um dieses Konzept zu verstehen, gehen wir von der Idee aus, das einzelne menschliche Neuron wie in der folgenden Abbildung zu replizieren.
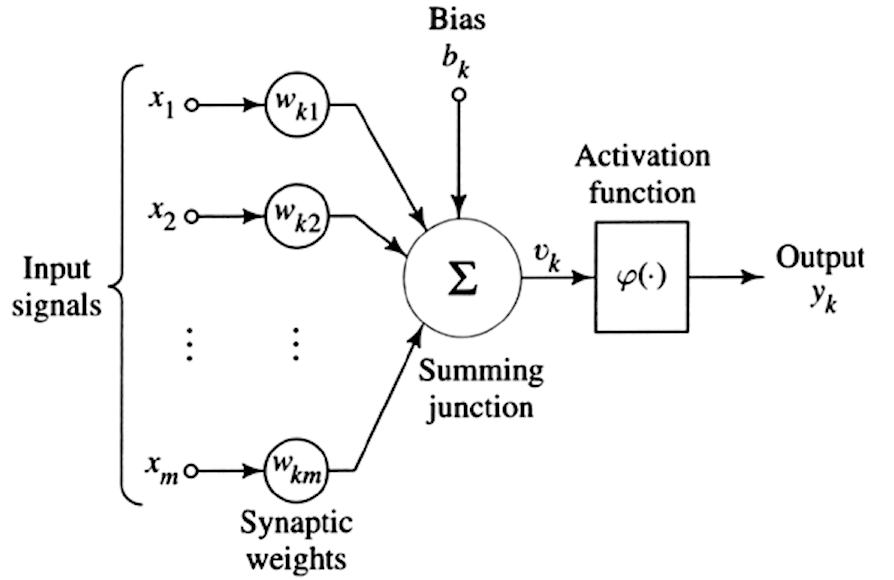
Wie zuvor beim maschinellen Lernen gesehen, haben wir eine Reihe von Eingangssignalen (links im Bild), denen wir verschiedene Gewichtungen (Wk) zuordnen, eine kognitive „Verzerrung“ (bk) hinzufügen, die eine Art Verzerrung ist, und schließlich anwenden eine Aktivierungsfunktion, d. h. eine mathematische Funktion wie eine Sigmoidfunktion, hyperbolischer Tangens, ReLU usw. die unter Berücksichtigung einer Reihe gewichteter Eingaben und unter Berücksichtigung einer Verzerrung eine Ausgabe (yk) zurückgibt.
Dies ist das einzelne künstliche Neuron. Um ein neuronales Netzwerk zu erstellen, werden die Ausgänge des einzelnen Neurons mit einem der Eingänge des nächsten Neurons verbunden, wodurch ein dichtes Netzwerk von Verbindungen entsteht, wie in der Abbildung unten gezeigt, die das tatsächliche darstellt Tiefes neuronales Netzwerk.
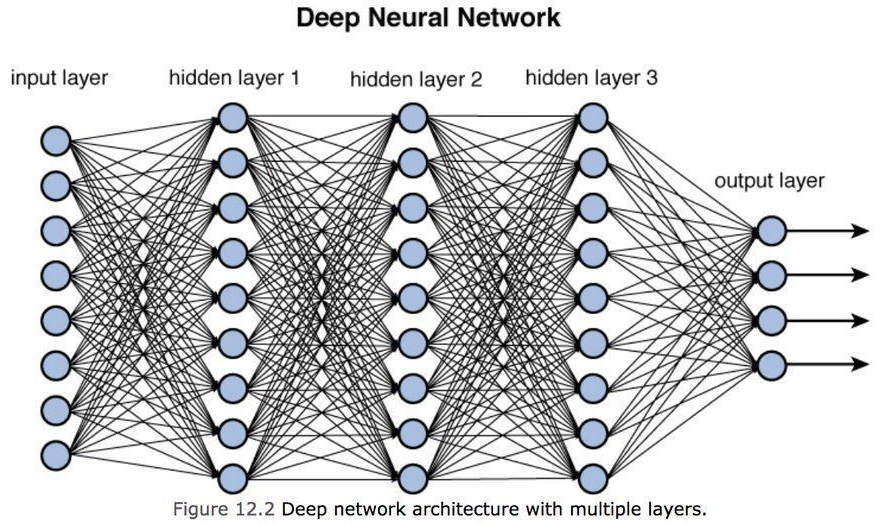
Tiefes Lernen
Wie wir aus der obigen Abbildung sehen können, haben wir eine Reihe von Eingaben, die dem neuronalen Netzwerk (Eingabeschicht) zugeführt werden müssen, dann Zwischenebenen, die als verborgene Schichten bezeichnet werden und die "Schichten" des Modells darstellen, und schließlich eine Ausgabeebene, die diskriminieren kann ( oder erkennen) ein Objekt über einem anderen. Wir können uns jede verborgene Schicht als Lernkapazität vorstellen: Je höher die Anzahl der Zwischenschichten (d. h. je tiefer das Modell), desto genauer wird das Verständnis, aber auch desto komplexer die durchzuführenden Berechnungen.
Beachten Sie, dass die Ausgabeschicht eine Reihe von Ausgabewerten mit einem bestimmten Wahrscheinlichkeitsgrad darstellt, z. B. 95 % einen Apfel, 4,9 % eine Birne und 0,1 % eine Banane und so weiter.
Stellen wir uns ein DL-Modell aus dem Bereich vor Computer Vision: die erste Schicht kann die Kanten des Objekts erkennen, die zweite Schicht ausgehend von den Kanten kann die Formen erkennen, die dritte Schicht ausgehend von den Formen kann komplexe Objekte erkennen, die aus mehreren Formen bestehen, die vierte Schicht ausgehend von Formen, die komplex sein können Details erkennen usw. Bei der Definition eines Modells gibt es keine genaue Anzahl von versteckte Schicht, aber die Grenze wird durch die Leistung auferlegt, die erforderlich ist, um das Modell in einer bestimmten Zeit zu trainieren.
Ohne zu sehr ins Detail zu gehen, hat das Training eines neuronalen Netzes als Ziel die Berechnung aller Gewichtungen und Vorspannungen, die auf alle im Modell vorhandenen einzelnen Neuronen anzuwenden sind: Es ist daher offensichtlich, dass die Komplexität exponentiell mit dem Zwischenwert zunimmt Schichten erhöhen (versteckte Schicht). Aus diesem Grund wurden für die Grafikkartenprozessoren (GPUs) verwendet TAUCHERAUSBILDUNG: Diese Karten eignen sich für anspruchsvollere Workloads, da sie im Gegensatz zu CPUs Tausende von Operationen parallel ausführen können, indem sie SIMD-Architekturen (Single Instruction Multiple Data) sowie moderne Technologien wie z Tensor-Kern die Matrixoperationen in Hardware ermöglichen.
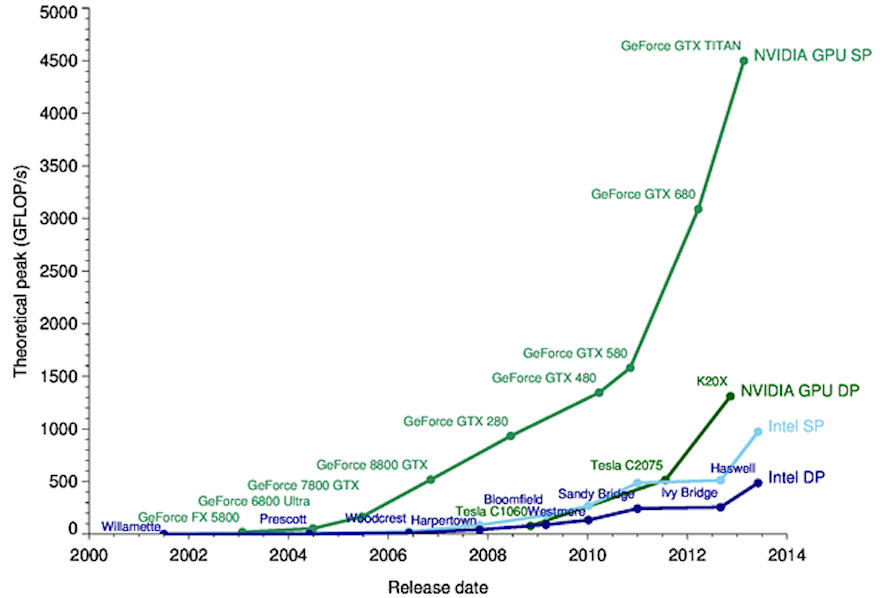
Deep-Learning-Anwendungen
Durch die Verarbeitung großer Datenmengen weisen diese Modelle trotz unvollständiger oder ungenauer Daten eine hohe Fehler- und Rauschtoleranz auf. Damit leisten sie grundlegende Unterstützung in allen Wissenschaftsbereichen. Lassen Sie uns einige von ihnen sehen.
Bildklassifizierung und Sicherheit
Im Falle von Verbrechen ermöglicht es die Erkennung eines Gesichts ausgehend von dem von einer Überwachungskamera aufgenommenen Bild und dem Vergleich mit einer Datenbank mit Millionen von Gesichtern: Dieser Vorgang könnte Tage, wenn nicht Monate oder sogar Jahre dauern, wenn er manuell von Menschen durchgeführt würde. Darüber hinaus ermöglichen einige Modelle durch die Rekonstruktion von Bildern, fehlende Teile derselben einzufärben, mit einer Genauigkeit von jetzt fast 100 % der Originalfarbe.
Verarbeitung natürlicher Sprache
Die Fähigkeit eines Computers, geschriebenen und gesprochenen Text genauso zu verstehen wie Menschen. Zu den bekanntesten Systemen gehören Alexa und Siri, die Fragen anderer Art nicht nur verstehen, sondern auch beantworten können.
Andere Modelle können das Sentiment-Analyse, immer mit Extraktionssystemen und Meinungen aus dem Text oder den Wörtern.
Medizinische Diagnosen
Im medizinischen Bereich werden diese Modelle heute zur Durchführung von Diagnosen verwendet, einschließlich der Analyse von CT- oder MRT-Scans. Die Ergebnisse, die in der Ausgangsschicht in einigen Fällen eine Zuverlässigkeit von 90–95 % haben, können eine Therapie für den Patienten ohne menschliches Eingreifen vorhersagen. Sie sind in der Lage, jeden Tag rund um die Uhr zu arbeiten, und können auch in der Phase der Patiententriage unterstützen, wodurch die Wartezeiten in einer Notaufnahme erheblich verkürzt werden.
Autonome Führung
Selbstfahrende Systeme erfordern eine kontinuierliche Überwachung in Echtzeit. Fortgeschrittenere Modelle sehen Fahrzeuge vor, die in der Lage sind, jede Fahrsituation unabhängig von einem Fahrer zu bewältigen, dessen Anwesenheit an Bord nicht vorgesehen ist, wobei nur die Anwesenheit von beförderten Passagieren vorgesehen ist.
Prognosen und Profilerstellung
Finanzielle Deep-Learning-Modelle ermöglichen es uns, Hypothesen über zukünftige Markttrends aufzustellen oder das Insolvenzrisiko eines Instituts genauer zu kennen, als es Menschen heute mit Interviews, Studien, Fragebögen und manuellen Berechnungen tun können.
Diese im Marketing verwendeten Modelle ermöglichen es uns, den Geschmack der Menschen zu kennen, um beispielsweise neue Produkte vorzuschlagen, basierend auf Assoziationen mit anderen Benutzern, die eine ähnliche Kaufhistorie haben.
Adaptive Entwicklungen
Basierend auf den hochgeladenen „Erfahrungen“ ist das Modell in der Lage, sich an Situationen anzupassen, die in der Umgebung oder aufgrund von Benutzereingaben auftreten. Adaptive Algorithmen bewirken eine Aktualisierung des gesamten neuronalen Netzes auf Basis neuer Interaktionen mit dem Modell. Stellen wir uns zum Beispiel vor, wie YouTube je nach Zeitraum Videos zu einem bestimmten Thema anbietet und sich Tag für Tag und Monat für Monat an unsere neuen persönlichen Vorlieben und Interessen anpasst.
Endlich, die Tiefes Lernen es ist immer noch ein schnell wachsendes Forschungsgebiet. Die Universitäten aktualisieren auch ihre Lehrprogramme zu diesem Thema, das immer noch eine solide mathematische Grundlage erfordert.
Die Vorteile der Anwendung des DL in Industrie, Forschung, Gesundheit und Alltag sind unbestritten.
Wir dürfen jedoch nicht vergessen, dass dies den Menschen unterstützen muss und dass dies nur in einigen begrenzten und sehr spezifischen Fällen den Menschen ersetzen kann. Tatsächlich gibt es bis heute keine „allgemeinen“ Modelle, die in der Lage sind, jede Art von Problem zu lösen.
Ein weiterer Aspekt ist die Verwendung dieser Vorlagen für illegale Zwecke wie das Erstellen von Videos Deepfake (siehe Artikel), d. h. Techniken, die verwendet werden, um andere Bilder und Videos mit Originalbildern oder -videos zu überlagern, um gefälschte Nachrichten, Betrug oder Rachepornos zu erstellen.
Eine weitere illegale Möglichkeit, diese Modelle zu verwenden, besteht darin, eine Reihe von Techniken zu entwickeln, die darauf abzielen, ein Computersystem zu kompromittieren, wie z. B. kontradiktorisches maschinelles Lernen. Durch diese Techniken ist es möglich, eine falsche Klassifizierung des Modells zu verursachen (und somit das Modell zu einer falschen Wahl zu veranlassen), Informationen über den verwendeten Datensatz zu erhalten (was zu Datenschutzproblemen führt) oder das Modell zu klonen (was Urheberrechtsprobleme verursacht).
Referenzen
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-int...
https://it.wikipedia.org/wiki/Lisp
https://it.wikipedia.org/wiki/Prolog
https://it.wikipedia.org/wiki/Apprendimento_supervisionato
https://www.enjoyalgorithms.com/blog/email-spam-and-non-spam-filtering-u...
https://foresta.sisef.org/contents/?id=efor0349-0030098
https://towardsdatascience.com/training-deep-neural-networks-9fdb1964b964
https://hemprasad.wordpress.com/2013/07/18/cpu-vs-gpu-performance/
https://it.wikipedia.org/wiki/Analisi_del_sentiment
https://www.ai4business.it/intelligenza-artificiale/auto-a-guida-autonom...
https://www.linkedin.com/posts/andrea-piras-3a40554b_deepfake-leonardodi...










